I am humbled and excited to help present alongside other sessions from some of the most respected names in the industry from Yahoo!, Google, Cloudera, Hortonworks, MapR, Microsoft. The growing depth, evolution, and community of the Big Data ecosystem is impressive, to say the least. I hope to attend other Hadoop customer sessions as well as investigate what other large players are accomplishing from their respective stacks. I see a lot of advanced sessions around new use-cases for Hadoop and research of adding additional layers and abstractions to Hadoop. The Adobe session is focused on the usability of Hadoop from an IT operations perspective with a few key points to make:
- Explain why virtualizing Hadoop is good from a business, techincal and operational perspective
- Accommodate the evolution and diversity of Big Data solutions
- Simplify the lifecycle deployment of these layers for engineering and operations.
- Create Hadoop-as-a-Service with VMware vSphere, Big Data Extensions, and vCloud Automation Center
Enter virtualization and everything I've been working on around virtualizing distributed systems, data analytics, Hadoop, and so forth. Consider the layering of functionality for different distributions and look for the similarities. If you take a look at Cloudera:

Or Hortonworks:
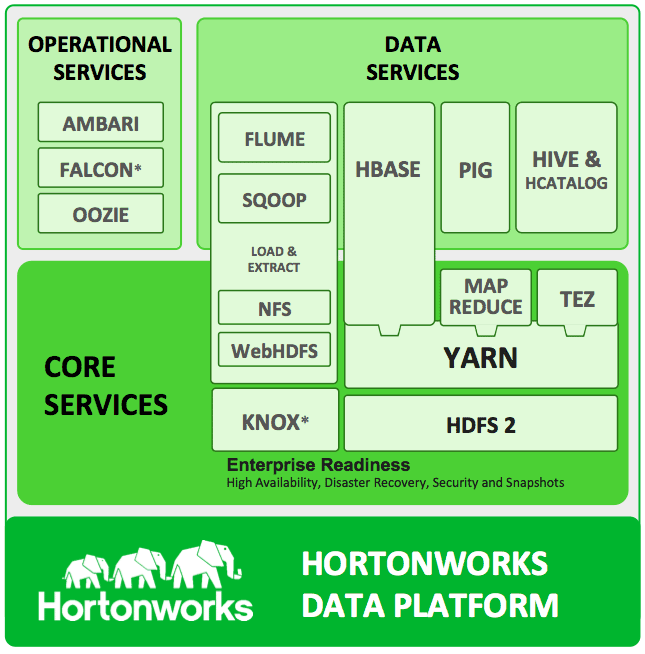

As a wise donkey once talked about in a movie when describing onions and cakes, they all have layers and so does any next-gen analytics platform. Now we have our data layer, and then a scheduling layer, then on top of that we can look at batch jobs, SQL jobs, streaming, machine learning, etc. Many moving parts and each one with probable workload variability per application, per customer. What abstraction layer helps pool resources, dynamically move components for elastic scale-in and scale-out and allows for flexible deployment of these many moving parts? Virtualization is a good answer, but also one of the first questions I get is "How's performance?" Well, I have seen vSphere scale and perform next to baremetal. Listed below is the link to the performance whitepaper detailing performance recommendations that have been tested on large clusters.
Speaking of all these layers, this leads to complexity very quickly so another angle specifically to the Adobe Hadoop Summit presentation is around hiding this complexity from the end-developers and making it easier and faster to develop, prototype, and release their analytics features into production. Some sessions are exploring even deeper, more complex uses of Hadoop and I am eager to see their results, however, enabling this lifecycle management for ops is essential to adoption of the latest functionality of any vendors' Big Data stack. VMware's Big Data Extensions, and in this case with vCloud Automation Center, allows for self-service consumption and easier experimentation. There's a (disputed) quote that has been attributed to Einstein that states "Everything should be made as simple as possible, but not simpler." There are a few vendors working on making Hadoop easier to consume and I would argue simplifying consumption of this technology is a worthwhile goal for the community. Dare I say even Microsoft's vision of allowing Big Data analysis via Excel is actually very intriguing if they can make it that simple to consume.
Another common question I get is "Virtualization is fine for dev/test, but how is it for production?" First, simplicity, elasticity, and flexibility are even more important to a production environment. And maybe more importantly, let's not discount the importance of experimentation to any software development lifecycle. As much as Hadoop enterprise vendors would like to make any Hadoop integration turnkey with any data source, any platform, any applications, I would argue we have a long way to go. Any innovation depends on experimentation and the ability to test out new algorithms, replacing layers of the stack, evaluating and isolating different variables in this distributed system.
One more assumption that keeps coming up is the perception that 100% utilization on a Hadoop cluster equals a high degree of efficiency. I am not a Java guru or an expert Hadoop programmer by any means, but if you think about it, it would be very easy for me to write something that drives a Yahoo! scale set of MapReduce nodes to 100% utilization but which really gives me no benefit whatsoever. Now take that a step further as that job can have some benefit to the user, but still be very resource inefficient. Quantifying that is worthy of more research but for now, optimizing the efficiency of any type of job or application specification will allow better business and operational intelligence to an organization and actually make their data lake (pond, ocean, deep murky loch?) worth the money.
Add to these business and operational justifications the added security posture:
http://virtual-hiking.blogspot.com/2014/04/new-roles-and-security-in-virtualized.html
and now you should have a much better idea of the solutions that forward-thinking customers are adopting to weaponize their in-house and myriad vendor analytics platforms.
Really exciting tech and hope to see you next week in San Jose!
Additional links
Hadoop Summit:
http://hadoopsummit.org/san-jose/schedule/
http://hadoopsummit.org/san-jose/speakers/#andrew-nelson
http://hadoopsummit.org/san-jose/speakers/#chris-mutchler
Hadoop performance case study and recommendations for vSphere:
http://blogs.vmware.com/vsphere/2013/05/proving-performance-hadoop-on-vsphere-a-bare-metal-comparison.html
http://www.vmware.com/files/pdf/techpaper/hadoop-vsphere51-32hosts.pdf
Open source Project Serengeti for Hadoop automated deployment on vSphere:
http://www.projectserengeti.org/
vSphere Big Data Extensions product page:
http://www.vmware.com/products/vsphere/features-big-data
How to set up Big Data Extensions workflows through vCloud Automation Center v6.0:
https://solutionexchange.vmware.com/store/products/hadoop-as-a-service-vmware-vcloud-automation-center-and-big-data-extension#.U4broC8Wetg
Big Data Extensions setup on vSphere:
https://www.youtube.com/watch?v=KMG1QlS6yag
HBASE cluster setup with Big Data Extensions:
https://www.youtube.com/watch?v=LwcM5GQSFVY
Big Data Extensions with Isilon:
https://www.youtube.com/watch?v=FL_PXZJZUYg
Elastic Hadoop on vSphere:
https://www.youtube.com/watch?v=dh0rvwXZmJ0
Excellent blog. It is really helpful and I want to learn the current updation of Big Data. Keep sharing more about Hadoop and Big Data.
ReplyDeleteHadoop Training in Chennai | Big Data Training in Chennai | Big Data Training
Your blog is so inspiring for the young generations.thanks for sharing your information with us and please update more new ideas.
ReplyDeleteGerman Training in Guindy
German Training in Ambattur
german language teaching institutes in bangalore
german training bangalore
Very interesting information that you have shared with us.i have personally thank you for sharing your ideas with us.
ReplyDeleteinstitutes to learn german in bangalore
german Training near me
German Training in Ambattur
German Training in Guindy
I really thank you for your innovative post.I have never read a creative ideas like your posts.here after i will follow your posts which is very much help for my career.
ReplyDeletevmware training center in bangalore
best vmware training institute in bangalore
Best vmware Training Institute in Anna nagar
vmware Training Institutes in Tnagar
Its a wonderful post and very helpful, thanks for all this information.
ReplyDeleteVmware Training institute in Noida